
Buffer Pool
Buffer Pool是内存中的缓存,主要是存了那些从磁盘中读出来的数据页
Buffer Pool带来的好处
减少disk操作,让速度更快 如果取的时候Page已经在Buffer Pool里了,那么就不需要再去从磁盘里取了。
Buffer Pool Manager 提供的API(简单版本)
- Page *FetchPage(page_id_t page_id) Read
- Page *NewPage(page_id_t *page_id) Write
- bool DeletePage(page_id_t page_id)
- bool UnpinPage(page_id_t page_id) 在处理Page的时候可能有多个线程在处理,那么如何保证Buffer Pool不把这个热Page踢出去呢? 因此引入了一个Pin操作,Pin操作会给这个Page加上一个counter,每开始用就会counter++,用完了counter–,然后当Buffer Pool Manager决定那些Page需要被换出时,其会去检查那个counter,如果这个counter==0 ,就意味着当前没有线程在用它,那么就Unpin,然后可以安全的把它换出内存。
Buffer Pool是如何实现的
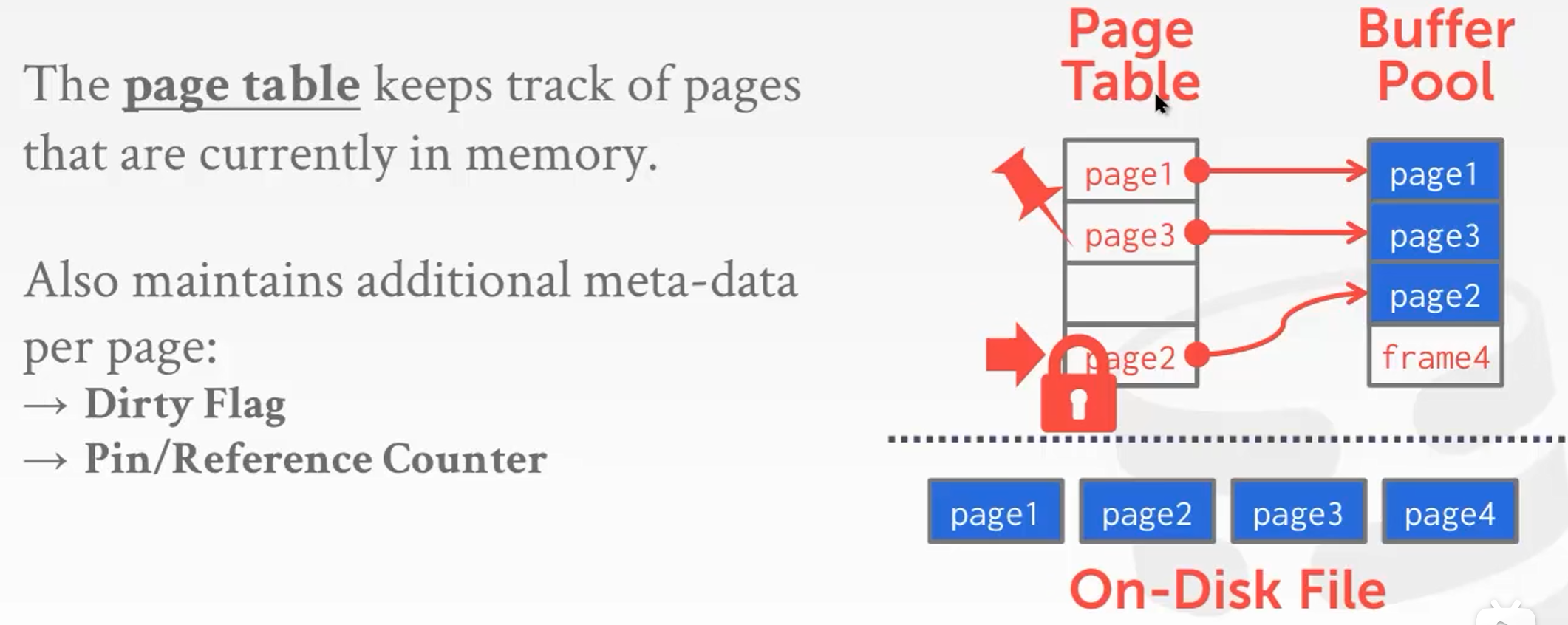
首先,page是存在最底层的磁盘文件上的,Buffer Pool其实就是一整块内存里的一小块,它用来存从disk里取出来的page,这些slot有一个专门的名字叫做frame,然后这些page存在里面。
上图的左侧有一个page表,page表中提供了一个映射, key是pageID,value是page在内存中的地址,由于提供的Api里传入的参数都是page_id,因此需要经过PageTable来找到Page具体的位置。
然后,每个page都有一个metadata,一个叫dirty flag(标志着这个page上是否更新了,但其还没有来得及刷入到磁盘,如果其没有被更新,那么Buffer Pool可以直接将其踢出,如果其更新了,Buffer Pool需要将其刷入磁盘),一个叫Pin/Reference Counter(防止把正在用的Page踢出去)。
针对Buffer Pool的其它一些优化:
- Multiple Buffer Pool: 一个Database里可能有多个Buffer Pool(分散针对于该数据库的读请求,那么一个Page可能出现在多个BufferPool里,这样就涉及到数据的一致性协议了),一个Database分配一个独立的Buffer Pool,好处就是不同负载的数据库之间不会影响,减少了锁竞争
- Pre-Fetching:根据查询计划可以预知接下来会需要哪些Page,当前线程在处理当前查询时,会有一个后台线程把未来会用到的数据预拉取,这样当CPU需要那些Page时,他们已经在内存里了,就不需要去磁盘中读了。
- Scan share:
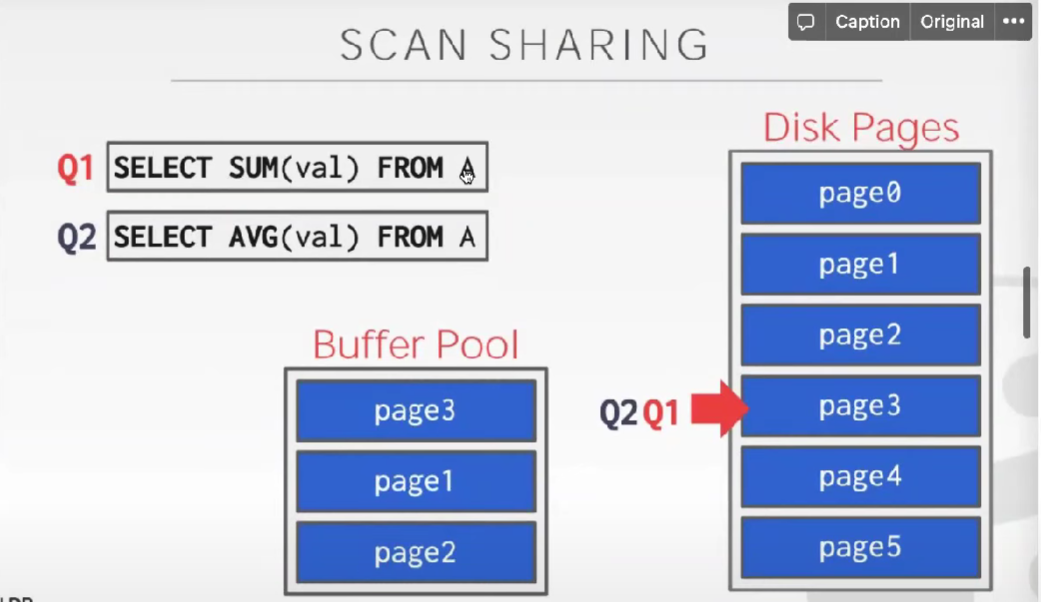
现在有两个查询Q1,Q2,它们要做的事情都差不多,都需要把A中所有的Page读出来,此时Q1已经把Page0-3里的数据都读出来,那么当Q2来的时候,Q2不需要从Page0开始再读一遍,Q2可以先跟着Q1的cursor一起读Page3,4,5,这样Page3,4,5只会被读1遍,然后Q1就执行完毕,后面Q2发现自己还有Page0,1,2没有读,然后它自己会去读Page0,1,2。相当于Page3,4,5被share了,就不需要读两遍。(这个优化只有一些比较高端Database才会支持 )
Buffer Pool满了怎么办?
选择淘汰策略的目标:能够尽可能的减少未来对磁盘的操作
- LRU 大部分DB使用该策略
- CLOCK

每一个Page存一个标志位,如果这个Page最近被访问了,就把这个ref设置为1,然后逻辑上来看在Page之间 有一个指针(它会顺时针的旋转,逆时针也可以,但是只能朝一个方向旋转),加入现在需要选择一个 Page将其踢出Buffer Pool,这个指针需要去寻找一个ref为0的Page,如果指针在转的过程中发现了ref为1的 Page,虽然此时不能把它踢出,但是会把该Page的ref置为0,置为0的意思就是等到指针转到下一圈时,它就 有可能会被踢出(如果在指针转到下一圈的过程中,这个Page又被访问了,那么它的ref又会是1,也就踢不 掉它)。
Why not OS cache ?
为什么不用操作系统自带的缓存,而使用DB自己实现的Buffer Pool呢
- DB比OS知道更多的信息(SQL语句,当前的负载,当前的查询,DB可以根据当前的查询来预测后面的查询,总的来说DB知道更多的信息,对于OS来说,这些对它没有区别)
- 大部分DB可以支持运行多种OS,但是OS之间的cache性能不同,导致DB在不同的OS上性能不同,如果是DB自己维护的话,性能就会好很多。
Static Hashing
- 静态Hash一般需要提前知道数据的数量
- 当Hash Table满了之后,需要重建一个更大容量的Hash Table,这个操作是非常损耗性能的
三个常见的静态Hash实现
-
线性探测Hash 如果没有冲突,直接插入,如果冲突了,就不停的玩后面找,知道没有冲突为止
-
Robin Hood hash
-
Cuckoo Hash
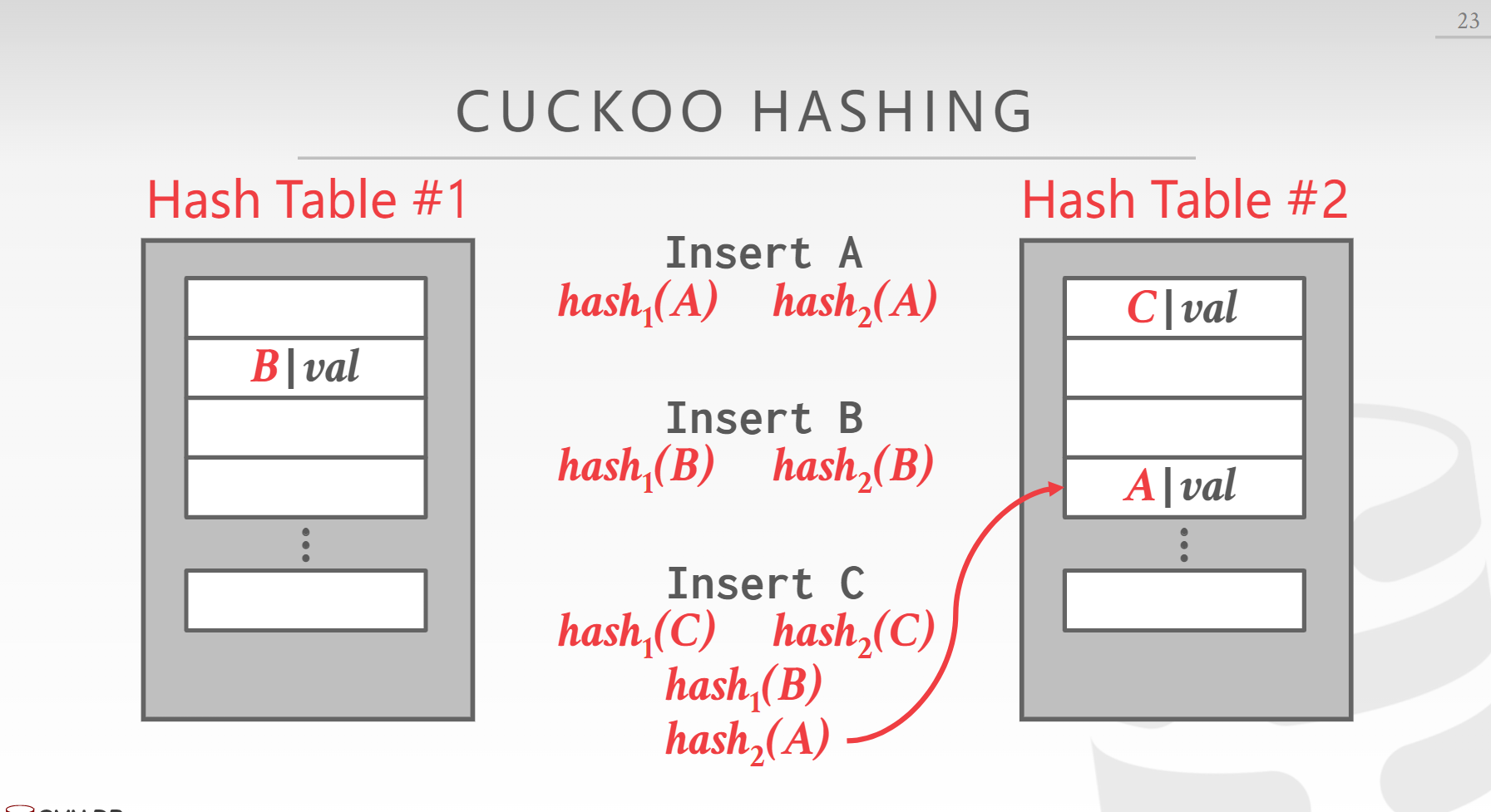
如果有冲突就把原来冲突的元素踢到另外一张表里,自己进去(这个动作很像杜鹃鸟)
比较拥挤的时候存在极端情况
Dynamic Hashing
- 逐步的增加HashTable,而不像静态Hash一样满了重建整个表
三个常见的动态Hash
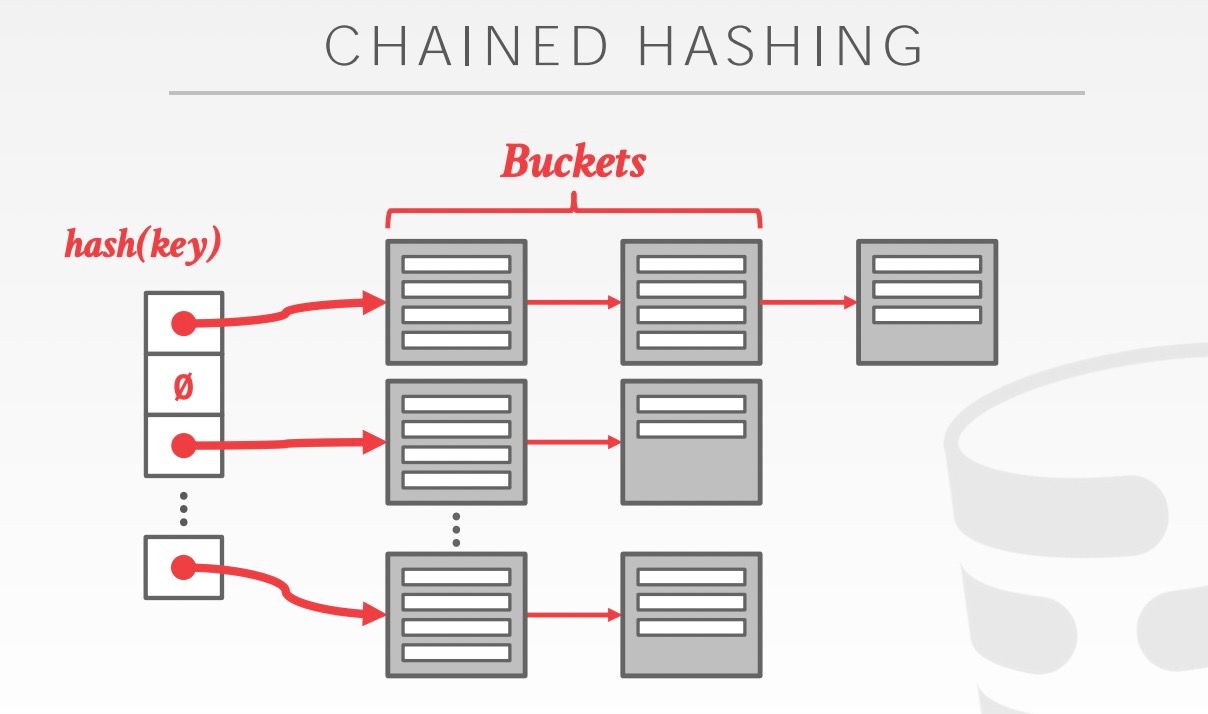
- Chained Hash
- Extendible Hash 通过调整Hash结果的位数来扩展
- Linear Hash




