
分布式一致性/共识算法
2PC
强一致性,中心化的原子(多个节点事务同时提交成功或同时失败)提交协议
场景:分布式事务,分布式副本
准备阶段 提交阶段
协调者(协调整个事务的提交和回滚),参与者(具体执行服务的节点)
**2PC第一阶段 ** 询问阶段
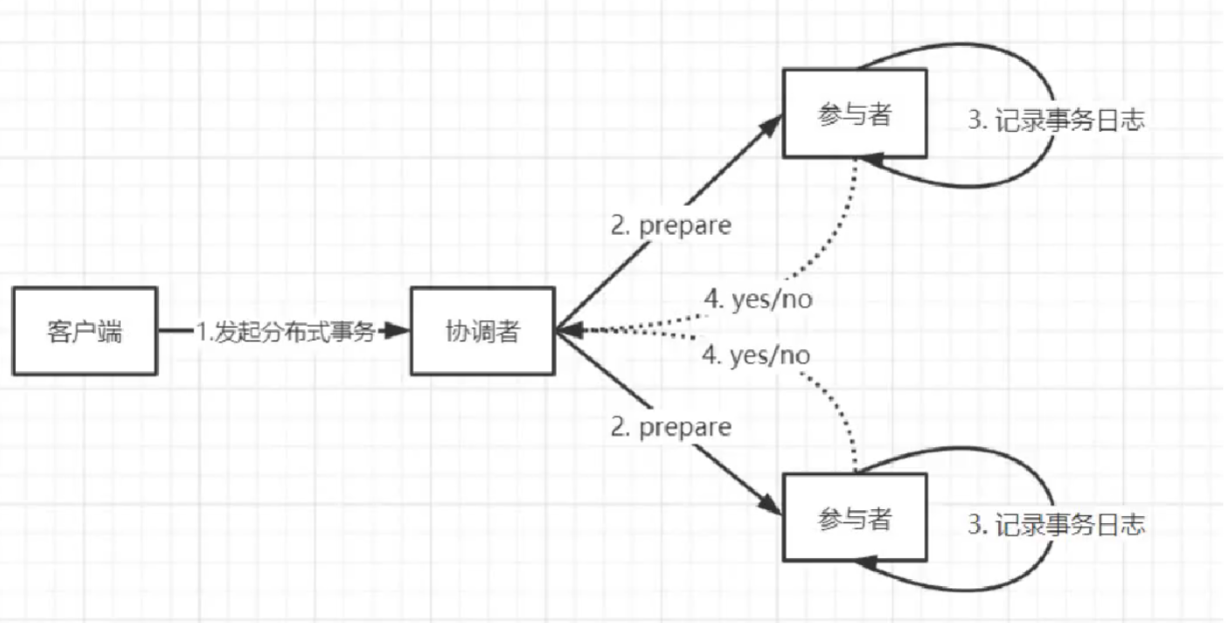
2PC第二阶段 提交阶段

2PC存在的问题:
同步阻塞 参与者需要等待协调者操作才能进行下阶段操作 协调者需要等待所有参与者的响应
数据不一致 在第二阶段广播globalcommit消息时还剩下一部分没有广播到时其宕机了 。或者因为网络的原因,一部分参与者没有收到globalcommit1的消息
单点问题(协调者宕机,集群就不可用了)/脑裂(集群比较大时出现网络分区,出现了多个协调者)
过于保守:等待所有的参与者成功才进行下一布,其实只要大多数成功就可以。
为了解决以上的部分问题,引入了3PC
3PC
强一致,中心化的原子提交协议
协调者,参与者
超时机制(解决2PC的同步阻塞): 参与者在等待协调者超时后,允许执行默认操作 协调者在等待参与者超时后,允许执行默认操作
降低了事务资源的锁定范围(解决了过于保守的问题): 增加了CanCommit阶段(相较于2PC多的一个阶段),不会像2PC一样一开始就锁定所有的事务资源,3PC在排除掉个别不具备处理事务能力参与者的前提下,再进入第二阶段的锁定事务资源
步骤: canCommit -> preCommit -> doCommit
相较于2PC的优化:
- 减少事务资源的锁定范围(增加canCommit阶段)
- 降低了同步阻塞(超时机制)
仍然存在的缺点:
- 增加了一轮消息,增加了复杂的和协商效率
- 数据不一致(引入超时机制,可能会导致数据不一致的问题)
Paxos
分布式共识算法
共识(Consensus):在一组允许出现故障的成员中,如何从一组提案(客户端发出的请求)中就某一个提案达成共识
共识与一致性:
- 共识强调从系统的外部来看,系统中的数据是一致的
- 一致性,是指系统中的所有节点数据100%真实是一致的
- 一致是包含共识
状态机:
- 确定性:一个确定的输入只会到达一个确定的状态
- 基于此,将集群中的多个成员都看作为状态机,那么只要控制所有状态机的输入,就能保证数据的最终状态是一致的。
应用场景:
- 区块链
- 后端架构
基本保证:
已达成共识的提案不会因为任何变故而改变
提案编号:
可以判断每个请求是迟到的消息还是过期的消息
多数派:
超过集群中超过一半以上成员组成的集合
角色:
- Proposer 处理客户端的请求,将这个请求封装为提案广播给所有的Acceptor,推进协商进程
- Acceptor 用于抉择提案
- Learner 用于学习已经达成共识的提案,并执行状态转移,执行状态机
阶段:
- Prepare阶段 协商阶段 争取本轮提出提案的所有权 获取上一轮可能已经达成共识的提案 不会真正提出提案值
- Accept阶段 协商阶段 真正提出提案值的阶段
- Learn阶段 状态转移
协商约定条件
Acceptor:令自己所见过的最大提案编号为local.n,请求中的提案编号为msg.n
- 收到Prepare请求,msg.n > local.n ,则通过该请求,否则拒绝该请求,直接抛弃该请求
- 收到Accept请求,msg.n >= local.n,则通过该请求,否则拒绝该请求,直接抛弃该请求
- 通过某一Prepare请求时,会在Prepare响应中携带自己批准过的最大提案编号对应的提案值
Proposer:
- 收到客户端请求,发起Prepare请求
- 收到多数派的Prepare响应,才可以进入Accept阶段。其提案值需要从Prepare响应中获取
- 收到多数派的Accept响应,泽该提案达成共识
Paxos与 2PC亦或是3PC的区别
2PC和3PC用于实现一个强一致性的系统,应用场景比如有分布式事务以及副本之间的同步复制
Paxos不会要求这么强的一致性,它允许出现系统中一半以内的成员发生故障。
MultiPaxos
原生Paxos的局限
每一个提案达成共识都需要两个阶段的协商,需要进行4轮的消息交互,协商效率不高
多个Proposer之间会互相影响 活锁
为了解决上述两个问题,提出了两个优化点,也就有了MultiPaxos
引入Leader角色
- 指的是能够发起提案的Proposer,减少了活锁发生的概率 Leader不唯一,我们允许在同一时刻存在多个Leader
优化Prepare阶段
- 在没有提案冲突的情况下,优化掉Prepare阶段,把协商过程优化成一个阶段
优化了Prepare阶段,允许Leader在只执行一轮Prepare的前提下,依次执行多次的Accept阶段,使得在一轮协商过程中可以有多个提案达成共识
优化了Prepare阶段:在没有提案冲突的情况下,也即没有其他的Leader争夺发起提案的所有权的时候,那么Prepare阶段可以一直省略掉,直接进入Accept阶段,但是如果有其他的Leader来跟当前的Leader争取发起提案的所有权的时候,那么这个Leader会递增编号,发起Prepare请求,这样就会使得原先拥有发起提案所有权的那个Leader得不到多数派的响应,致使其协商失败
Zookeeper为什么不用Paxos ?
Paxos 的局限性
- 消息交互次数过多
- 活锁问题
- 工程实现上难度过大
- 缺少一些必要的模块实现,例如:log对齐(少数如何服从多数),成员变更,snapshot,崩溃恢复
ZAB
集群中的角色:
- Leader 在同一个epoch中是强leader算法,leader唯一。多个epoch可能有多个leader
- Follower
- Observer 只会被动的接受提案,不会参与提案的协商,意味着它收到的提案都是已经达成共识的,也就意味着它可以处理读请求。当集群中的读请求性能不够时,我们可以拓展观察者的数量。在提升读请求时又不会影响写请求的效率。跨地域优化,读自己地域内的观察者
成员状态:
- election 这个状态会尝试选举leader
- follower 其他节点就是跟随状态
- leading leader是领导状态
- observing 观察者的状态
运行阶段:
-
选举阶段
可以使用任意的选举算法来代替,在ZAB论文中没有具体的描述,保证选举出一个leader即可
用于集群刚启动的时候或者说成员中的leader宕机的情况下
大致过程: 首先所有的成员都会先支持自己成为leader,然后把支持自己成为leader的信息广播给其他成员,然后其他的成员根据这个选票的信息和自己本地的数据做对比,然后选出一个提案数据最完整的成员当作leader,然后再广播给其他成员,当集群中有一个成员获得到多数派的支持,它就会晋升为准leader。
myid:标志着每一个成员的唯一ID
选举胜利的条件:
任期编号(epoch),优先判断被投票者的epoch,epoch大的选票获胜。 事务标示符(zxid),被投票者的epoch相同,则比较被投票者的zxid(判断的是zxid中的countor),zxid大的选票获 胜。 myid,若epoch、zxid都一致,则比较myid(在myid文件中指定的值),myid大的选票 获胜。因为myid在集群中不允许重复,所以该判断一定能选出一个获胜的选票。
-
成员发现
当选举出一个leader后,所有的跟随者会去主动联系这个准leader,然后跟准leader协商出一个epoch。
作用:为了产生下一个leader周期,而使得旧leader周期产生的提案不会再达成共识。因为所有的跟随者在接收提案的时候会去判断消息的有效性。epoch就是判断的标准
大致过程:变成follower的节点会主动的联系leader
-
数据同步
多数派的运行就可以保证算法的协商,所以会存在少数派的成员数据不一致的问题,ZAB会在数据同步阶段把最新的提案list发送给所有的跟随者,使得所有的跟随者跟leader有相同的数据,也即数据对齐
ZAB分为3中数据同步
- DIFF 只会同步差异数据
- Snapshot 快照同步
- Trunc 有可能该跟随者是上一任的leader,它提出提案之后没有把这个提案广播到集群中,那么这个提案就只在它本身中拥有,所以它以跟随者加入到集群中的时候,leader会要求它把这些提案给删除
-
消息广播
在Zookeeper完成数据对齐后,集群就可以对外提供服务了,消息广播阶段就是真实的处理客户端的事务请求,此时准leader已经成为leader了,它会为每一个跟随者维护一个队列,leader要发送所有的消息给跟随者的时候,是通过队列一个一个发送的。
事务标识符(zxid :标志一个提案的唯一值)
zxid中的两个字段,如下
- epoch 当前leader所处的周期,就是协商下一个leader的周期
- Countor 当前leader自己提出过的所有提案的一个计数,单调递增的整数
多数派: 一半以上成员组成的集合
论文中理论与工程具体实践的区别:
- CEPOCH ->FOLLOWERINFO
- NEWEPOCH->LEADERINFO
- ACK-E -> ACKEPOCH
- NEWLEADER->NEWLEADER
- ACK-LD->ACKKNOWLEA
Raft
简介:
多数派
任期(term)
强Leader的“一阶段”算法
成员状态
- Leader
- Candidate
- Follower
- 在实际实现时可以加入Witness和无投票权的成员
运行阶段
- Leader选举
- 日志复制
RPC消息类型
- RequestVote:请求投票信息,用于选举Leader
- AppendEntries:追加条目信息
- 用于向Follower执行日志复制
- 用于Leader与Follower之间的心跳检测
- 用于Leader与Follower之间的日志对齐
超时机制(在Raft中超时后的下一次操作的时间都是随机的 这样做可以大概率规避多节点同时发起选举的情况发生):
- Follower等待心跳超时
- 等待选举投票超时
投票规则:
- term大的成员拒绝给term小的RequestVote消息(Leader任期高的成员不会投票给Leader任期小的RequestVote消息)
- 最后一条日志项编号(uncommitted)大的拒绝投票给最后一条日志项编号(uncommitted)小的成员(日志编号大的成员会拒绝投票给日志编号小的成员),这一操作可以保证新选举出的Leader有最完整的数据
- 每个成员,一届term任期内只投出一张选票,先来先获得选票
日志复制
日志项(存放提案) Raft所有的协商过程都是以日志项的形式进行协商
日志项只能由Leader流入到Follower,Follower不能以任何形式覆盖掉Leader的日志项
日志索引,全局唯一且连续递增的整数编号,用于标识每个日志项在日志列表中所处的位置。其连续性不限于多个Leader周期之间
- 日志索引是连续的当新Leader晋升的时候,不需要考虑新Leader的本地日志中是否存在空洞的日志,比如在Paxos中,新Leader晋升后,它就要先获取到集群中所有其他成员的最大提案,然后以最大的提案来补充它所缺少的那些提案
- 通过最大的日志项,Raft就能比较两个成员之间的差异数据
##




